이번시간에는 파이썬으로 텍스트-음성 변환하는 라이브러리들을 살펴보도록하겠습니다. 본강의는 맥북기준으로 진행됩니다.
pyttsx3
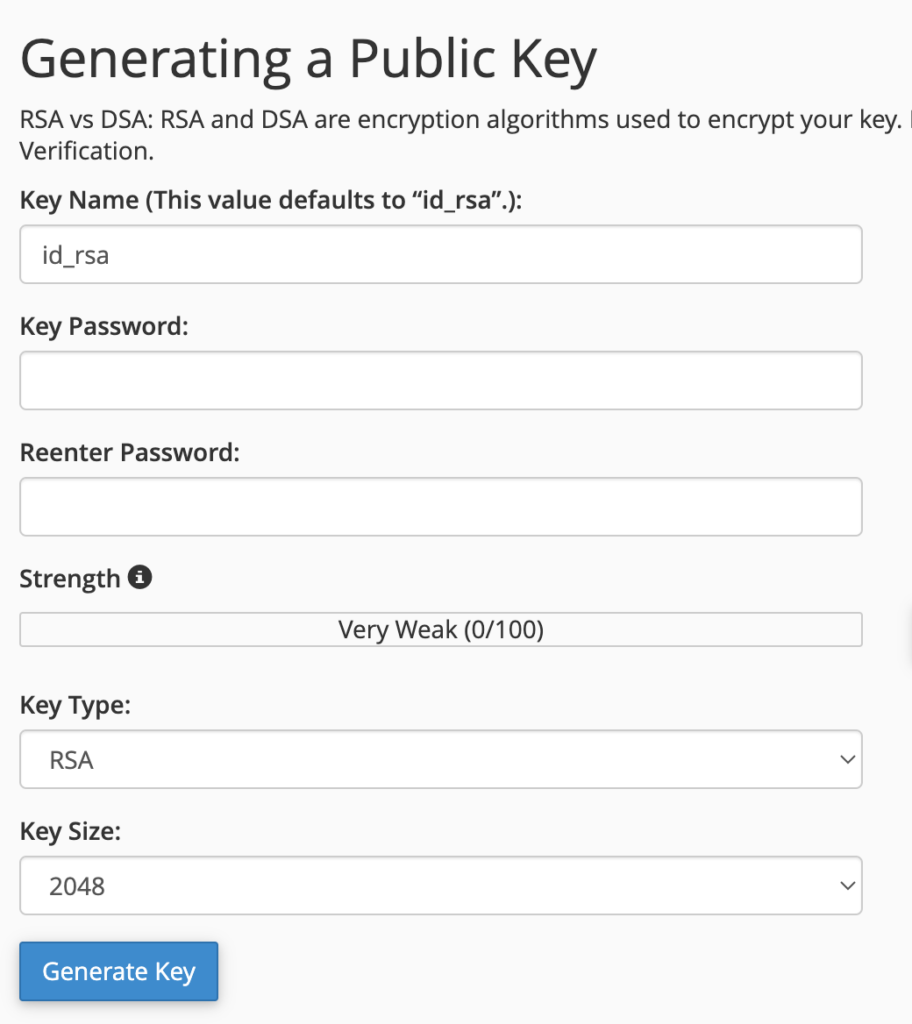
우선 대표적인 것으로는 pyttsx3가 있는데, 단 버젼은 pyttsx3==2.99로 설치하셔야합니다. 최근버젼에 버그가 있어서 현재시간으로는 아직 개선중인것 같습니다(참고). 2.99버젼은 pip에는 없고 https://test.pypi.org/simple/에서 가져다 설치하셔야해요.
pip install --no-cache-dir --extra-index-url https://test.pypi.org/simple/ pyttsx3==2.99
코드는 아래와 같이 사용합니다.
import pyttsx3
engine = pyttsx3.init()
text = "Hello, world!"
engine.save_to_file(text, "output_pyttsx3.mp3")
engine.runAndWait()
추가적인 옵션으로는 속도를 변경하려면 rate속성을 바꾸면 됩니다.
engine.setProperty('rate', 125)
볼륨을 변경하시려면 volume의 값을 변경하시면 되는데, 0에서 1사이의 값을 넣습니다.
engine.setProperty('volume',0.9)
그리고 목소리도 변경할 수가 있는데, voice속성에 변경할 voice ID를 할당하시면 됩니다.
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[66].id)
참고로 pyttsx3에서 지원하는 voice들은 아래와 같습니다(배열방번호, ID, name, 언어, 성별, 나이).
0,com.apple.speech.synthesis.voice.Agnes,Agnes,en_US,VoiceGenderFemale,35
1,com.apple.speech.synthesis.voice.Albert,Albert,en_US,VoiceGenderNeuter,30
2,com.apple.speech.synthesis.voice.Alex,Alex,en_US,VoiceGenderMale,35
3,com.apple.speech.synthesis.voice.alice,Alice,it_IT,VoiceGenderFemale,35
4,com.apple.speech.synthesis.voice.allison.premium,Allison,en_US,VoiceGenderFemale,35
5,com.apple.speech.synthesis.voice.alva,Alva,sv_SE,VoiceGenderFemale,35
6,com.apple.speech.synthesis.voice.amelie,Amelie,fr_CA,VoiceGenderFemale,35
7,com.apple.speech.synthesis.voice.anna,Anna,de_DE,VoiceGenderFemale,35
8,com.apple.speech.synthesis.voice.ava.premium,Ava,en_US,VoiceGenderFemale,35
9,com.apple.speech.synthesis.voice.BadNews,Bad News,en_US,VoiceGenderNeuter,50
10,com.apple.speech.synthesis.voice.Bahh,Bahh,en_US,VoiceGenderNeuter,2
11,com.apple.speech.synthesis.voice.Bells,Bells,en_US,VoiceGenderNeuter,100
12,com.apple.speech.synthesis.voice.Boing,Boing,en_US,VoiceGenderNeuter,1
13,com.apple.speech.synthesis.voice.Bruce,Bruce,en_US,VoiceGenderMale,35
14,com.apple.speech.synthesis.voice.Bubbles,Bubbles,en_US,VoiceGenderNeuter,0
15,com.apple.speech.synthesis.voice.carmit,Carmit,he_IL,VoiceGenderFemale,35
16,com.apple.speech.synthesis.voice.Cellos,Cellos,en_US,VoiceGenderNeuter,50
17,com.apple.speech.synthesis.voice.damayanti,Damayanti,id_ID,VoiceGenderFemale,35
18,com.apple.speech.synthesis.voice.daniel,Daniel,en_GB,VoiceGenderMale,35
19,com.apple.speech.synthesis.voice.Deranged,Deranged,en_US,VoiceGenderNeuter,30
20,com.apple.speech.synthesis.voice.diego,Diego,es_AR,VoiceGenderMale,35
21,com.apple.speech.synthesis.voice.ellen,Ellen,nl_BE,VoiceGenderFemale,35
22,com.apple.speech.synthesis.voice.fiona,Fiona,en-scotland,VoiceGenderFemale,35
23,com.apple.speech.synthesis.voice.Fred,Fred,en_US,VoiceGenderMale,30
24,com.apple.speech.synthesis.voice.GoodNews,Good News,en_US,VoiceGenderNeuter,8
25,com.apple.speech.synthesis.voice.Hysterical,Hysterical,en_US,VoiceGenderNeuter,30
26,com.apple.speech.synthesis.voice.ioana,Ioana,ro_RO,VoiceGenderFemale,35
27,com.apple.speech.synthesis.voice.joana,Joana,pt_PT,VoiceGenderFemale,35
28,com.apple.speech.synthesis.voice.jorge,Jorge,es_ES,VoiceGenderMale,35
29,com.apple.speech.synthesis.voice.juan,Juan,es_MX,VoiceGenderMale,35
30,com.apple.speech.synthesis.voice.Junior,Junior,en_US,VoiceGenderMale,8
31,com.apple.speech.synthesis.voice.kanya,Kanya,th_TH,VoiceGenderFemale,35
32,com.apple.speech.synthesis.voice.karen,Karen,en_AU,VoiceGenderFemale,35
33,com.apple.speech.synthesis.voice.Kathy,Kathy,en_US,VoiceGenderFemale,30
34,com.apple.speech.synthesis.voice.kyoko,Kyoko,ja_JP,VoiceGenderFemale,35
35,com.apple.speech.synthesis.voice.laura,Laura,sk_SK,VoiceGenderFemale,35
36,com.apple.speech.synthesis.voice.lekha,Lekha,hi_IN,VoiceGenderFemale,35
37,com.apple.speech.synthesis.voice.luca,Luca,it_IT,VoiceGenderMale,35
38,com.apple.speech.synthesis.voice.luciana,Luciana,pt_BR,VoiceGenderFemale,35
39,com.apple.speech.synthesis.voice.maged,Maged,ar_SA,VoiceGenderMale,35
40,com.apple.speech.synthesis.voice.mariska,Mariska,hu_HU,VoiceGenderFemale,35
41,com.apple.speech.synthesis.voice.meijia,Mei-Jia,zh_TW,VoiceGenderFemale,35
42,com.apple.speech.synthesis.voice.melina,Melina,el_GR,VoiceGenderFemale,35
43,com.apple.speech.synthesis.voice.milena,Milena,ru_RU,VoiceGenderFemale,35
44,com.apple.speech.synthesis.voice.moira,Moira,en_IE,VoiceGenderFemale,35
45,com.apple.speech.synthesis.voice.monica,Monica,es_ES,VoiceGenderFemale,35
46,com.apple.speech.synthesis.voice.nora,Nora,nb_NO,VoiceGenderFemale,35
47,com.apple.speech.synthesis.voice.paulina,Paulina,es_MX,VoiceGenderFemale,35
48,com.apple.speech.synthesis.voice.Organ,Pipe Organ,en_US,VoiceGenderNeuter,500
49,com.apple.speech.synthesis.voice.Princess,Princess,en_US,VoiceGenderFemale,8
50,com.apple.speech.synthesis.voice.Ralph,Ralph,en_US,VoiceGenderMale,50
51,com.apple.speech.synthesis.voice.rishi,Rishi,en_IN,VoiceGenderMale,35
52,com.apple.speech.synthesis.voice.samantha.premium,Samantha,en_US,VoiceGenderFemale,35
53,com.apple.speech.synthesis.voice.sara,Sara,da_DK,VoiceGenderFemale,35
54,com.apple.speech.synthesis.voice.satu,Satu,fi_FI,VoiceGenderFemale,35
55,com.apple.speech.synthesis.voice.sinji,Sin-ji,zh_HK,VoiceGenderFemale,35
56,com.apple.speech.synthesis.voice.tessa,Tessa,en_ZA,VoiceGenderFemale,35
57,com.apple.speech.synthesis.voice.thomas,Thomas,fr_FR,VoiceGenderMale,35
58,com.apple.speech.synthesis.voice.tingting,Ting-Ting,zh_CN,VoiceGenderFemale,35
59,com.apple.speech.synthesis.voice.Trinoids,Trinoids,en_US,VoiceGenderNeuter,2001
60,com.apple.speech.synthesis.voice.veena,Veena,en_IN,VoiceGenderFemale,35
61,com.apple.speech.synthesis.voice.Vicki,Vicki,en_US,VoiceGenderFemale,35
62,com.apple.speech.synthesis.voice.Victoria,Victoria,en_US,VoiceGenderFemale,35
63,com.apple.speech.synthesis.voice.Whisper,Whisper,en_US,VoiceGenderNeuter,30
64,com.apple.speech.synthesis.voice.xander,Xander,nl_NL,VoiceGenderMale,35
65,com.apple.speech.synthesis.voice.yelda,Yelda,tr_TR,VoiceGenderFemale,35
66,com.apple.speech.synthesis.voice.yuna,Yuna,ko_KR,VoiceGenderFemale,35
67,com.apple.speech.synthesis.voice.yuri,Yuri,ru_RU,VoiceGenderMale,35
68,com.apple.speech.synthesis.voice.Zarvox,Zarvox,en_US,VoiceGenderNeuter,1
69,com.apple.speech.synthesis.voice.zosia,Zosia,pl_PL,VoiceGenderFemale,35
70,com.apple.speech.synthesis.voice.zuzana,Zuzana,cs_CZ,VoiceGenderFemale,35
음성출력은 아래와 같이 say()함수에 말할 텍스트를 넘겨주면 됩니다.
engine.say("Hello World!")
음성파일을 저장하시려면 아래와 같이 save_to_file()함수에 텍스트와 저장할 파일경로를 넘겨주시면 됩니다.
engine.save_to_file("Hello World!", "output_pyttsx3.mp3")
어떤 이유에서인지 pyttsx3는 mpg123로는 출력이 안되네요.
gtts
이번에는 gtts를 이용해서 TTS를 구현해 보도록 하겠습니다.
gtts를 설치해주세요.
pip install gtts
그리고 tts_with_gtts.py를 생성해서 아래 코드를 저장해주세요.
from gtts import gTTS
tts = gTTS("Hello, world!", lang="en")
tts.save("output_gtts.mp3")
실행해 보시면 output_gtts.mp3가 생성되어 있을거에요.
python tts_with_gtts.py
gtts로 만든 파일은 mpg123를 이용해서 재생할 수 있습니다.
mpg123 output_gtts.mp3
그런데 얘는 다양한 목소리 지원이나 속도, 볼륨조절등의 옵션은 없어요.