Overview
안녕하세요. 이번시간에는 Google에서 제공하는 API를 이용하는 방법에 대해서 알아보도록 하겠습니다.
Create Project
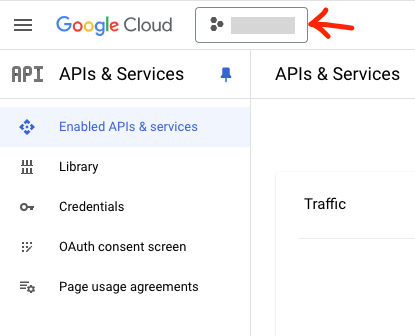
Google의 API들을 사용하시려면 Google Cloud에 프로젝트를 생성하셔야합니다. Google Cloud의 APIs & Services대시보드를 열어주세요. 그리고 상단에 프로젝트 이름을 클릭하면 현재 프로젝트들이 보이는 팝업을 뜨는데요.
저는 기존에 있는 프로젝트가 2016년도에 만들어진 것들이라서 해당 프로젝트로 API에 접근하려고 보니까 API사용 quota가 다 소진되었다고 나와요. 하루 10,000번의 request가 가능한데 저 2번 요청했거든요. 근데 찾아보니까 옛날에 만들어진 프로젝트에서 나오는 오류라고 하더라구요. 그래서 저도 이번에 프로젝트를 새로 만들었습니다. 여기에서 상단에 NEW PROJECT버튼을 누르세요.
그러면 프로젝트 생성하는 양식이 나타납니다. 프로젝트 이름을 넣고 Create버튼을 눌러주세요.
그러면 해당 프로젝트의 대시보드가 눈앞에 펼쳐집니다.

Enable APIs
왼쪽 메뉴에서 Library를 누르세요. 그러면 사용가능한 모든 API를 보여줍니다.
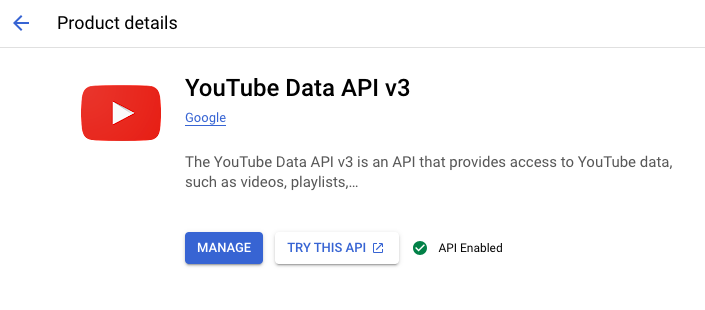
앞으로 하나하나 다 사용해보겠지만 우선 YouTube Data API v3를 선택할게요. 밑으로 스크롤 내리다보면 YouTube섹션에 가장 처음 나오는 API인데 검색해도 나오니까 선택해주세요. 그러면 API에 대한 상세한 설명이 나오는데 여기에서 ENABLE버튼을 클릭해주세요. 다른 API도 필요하실때 라이브러리에서 Enable을 시켜주셔야 사용이 가능합니다.
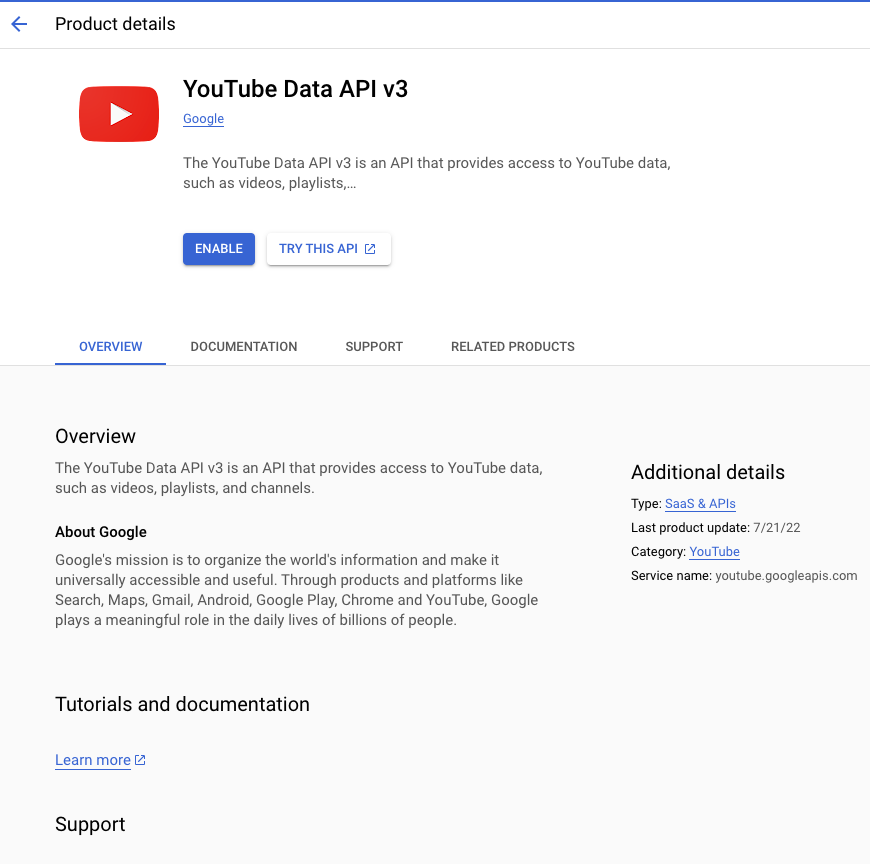
Enable시키면 아래와 같이 API사용이 허용됩니다.
Authentication
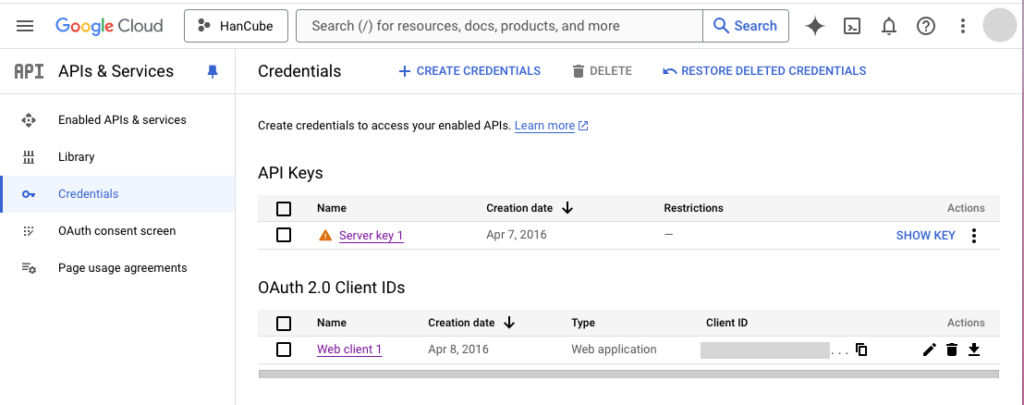
Google의 API를 사용하려면 우선 인증키가 필요합니다. 인증을 하는 방법에는 간단하게 API Key를 사용하는 방법과 OAuth를 사용하는 방법 두가지가 있습니다. Google Cloud의 APIs & Services에 들어가면 아래 화면과 같이 Credential들을 확인하실 수 있습니다.
API Key
Create API Key
API Key를 생성하시려면 상단에 +Create Credentials을 클릭하면 API Key를 생성할지 OAuth Client ID를 생성할지를 물어봅니다. 여기서 API Key를 선택합니다.
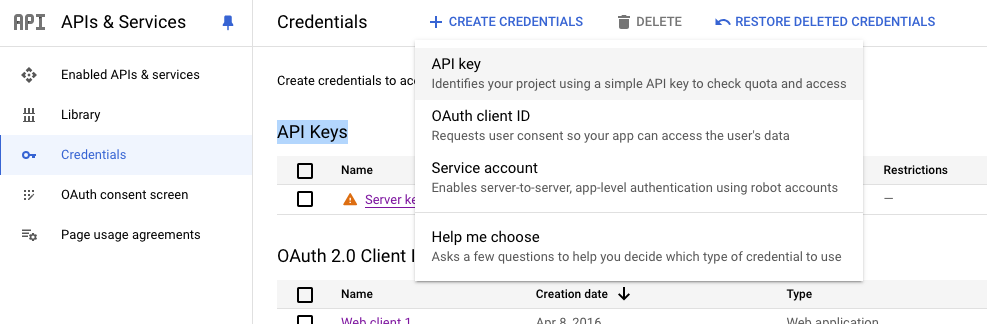
그러면 다른거 안물어보고 바로 API Key를 하나 생성해서 보여줍니다.
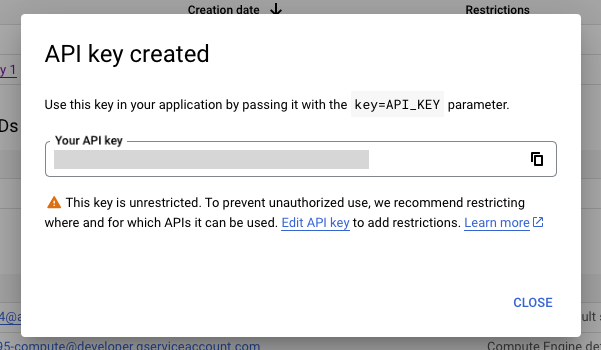
위에 경고문에 이 API key를 갖고 뭐든지 할수 있으니 권한을 조정하시오라고 써있습니다. Edit API Key를 눌러서 허용범위를 좁혀볼게요. 접근할 수 있는 클라이언트는 제한을 두지 않았고, 접근가능한 API는 YouTube Data API v3만 허용하는 걸로 변경했습니다.
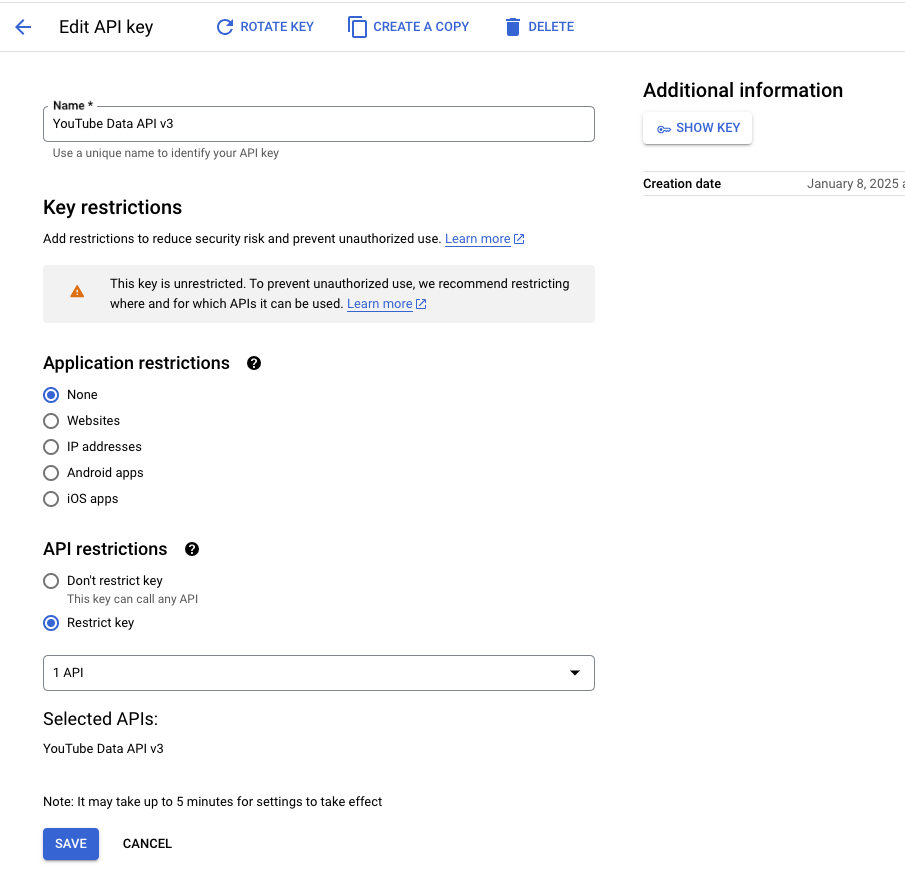
API Key를 이용한 API호출
그래도 구글인데 ?key=API_KEY를 쿼리스트링으로 암호화없이 그냥 보낸다고? 이건 진짜..큰일나는데…구글이 왜그랬지? 그밑에는 헤더에 넣어서 보내긴 하지만 헤더도 얼마든지 해킹이 가능한데..이건 진짜 너무 심했다…서비스가 너무 커서 예전 인증방식을 업그레이드 하는게 시간이 많이 걸렸나? 아직도 API_KEY방식을 지원하는 것도 좀 우습고..돈도 잘버는데 개발자들 팍팍 써서 싹 다 갈아엎어 버리지 이걸 그냥 이렇게 쓰냐….쯪….
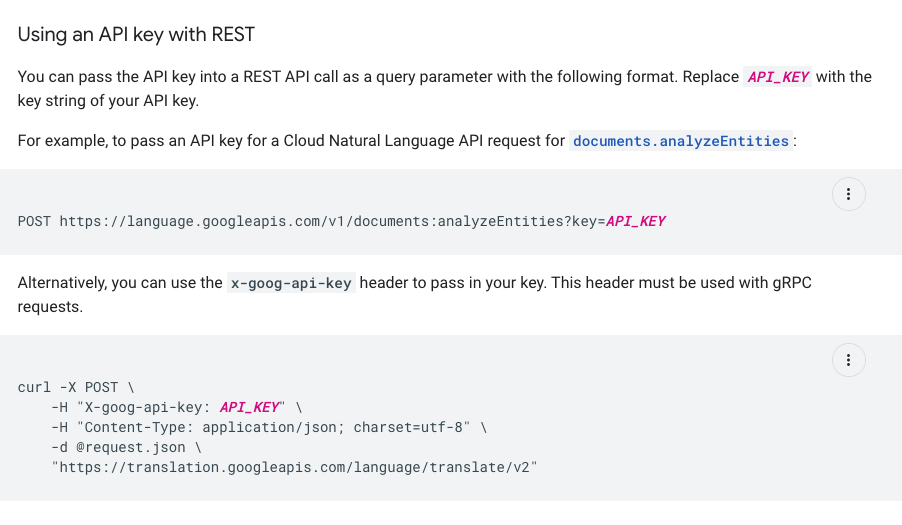
생성한 API Key를 가지고 API를 호출해볼게요. 결과가 잘 나옵니다.
$ curl -X GET \
> "https://content-youtube.googleapis.com/youtube/v3/videoCategories?part=snippet&id=1" \
> -H "X-goog-api-key: API_KEY" \
> -H "Content-Type: application/json; charset=utf-8"
{
"kind": "youtube#videoCategoryListResponse",
"etag": "s6RguhiCzdsBQFsS4YzslvqtQtI",
"items": [
{
"kind": "youtube#videoCategory",
"etag": "grPOPYEUUZN3ltuDUGEWlrTR90U",
"id": "1",
"snippet": {
"title": "Film & Animation",
"assignable": true,
"channelId": "UCBR8-60-B28hp2BmDPdntcQ"
}
}
]
}API Key삭제
APIs & Services > Credentials에 들어가시면 API Key목록이 보입니다. 오른쪽 점세개 누르시면 Delete API Key메뉴가 뜰거에요. 그거 누르세요.
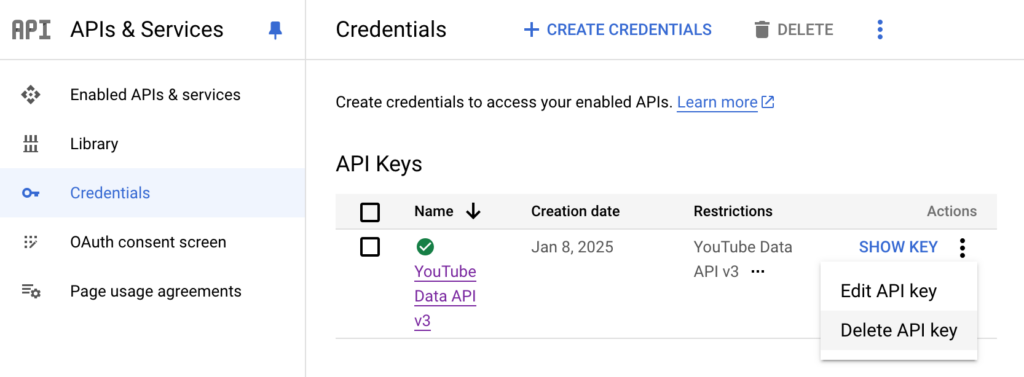
진짜 지울거냐고 물어보고
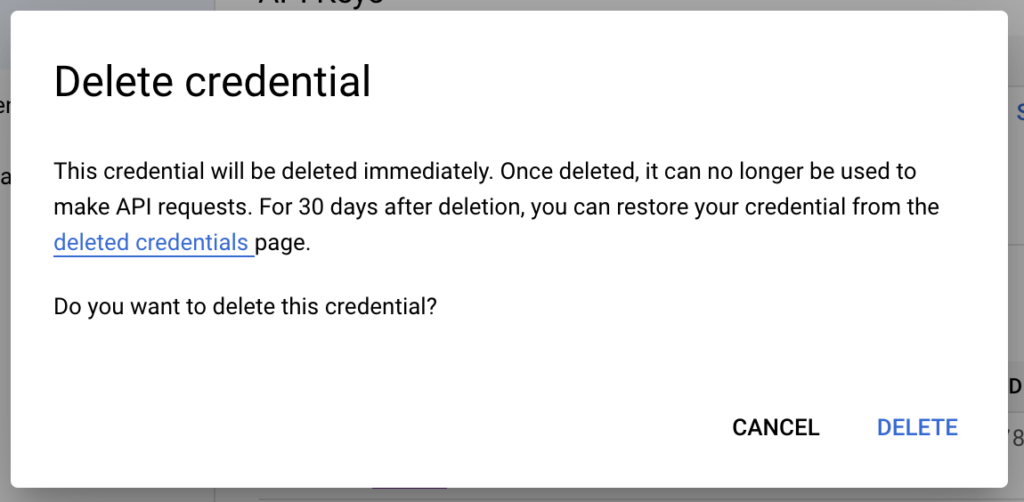
DELETE버튼 누르면 텍스트상자에 DELETE라고 입력하라고 나와요.
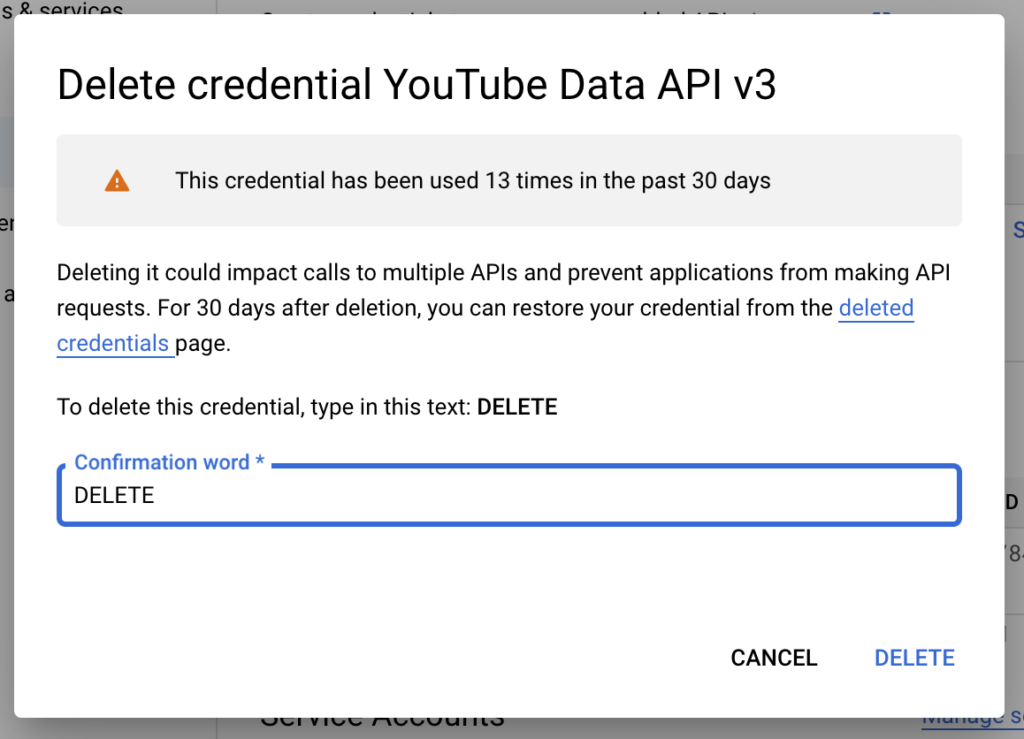
DELETE라고 쓰고 밑에 DELETE버튼 누르면 API Key가 삭제됩니다. 사용하지 않는 API Key들은 전부 삭제하시는게 보안상 안전합니다.
OAuth
API Key를 매번 사용하는 것은 보안상 매우 취약하기 때문에 가급적 OAuth Client ID를 이용해서 토큰을 받아와서 그걸로 API를 호출하는 방식으로 하는것을 추천드립니다.
Create OAuth client ID
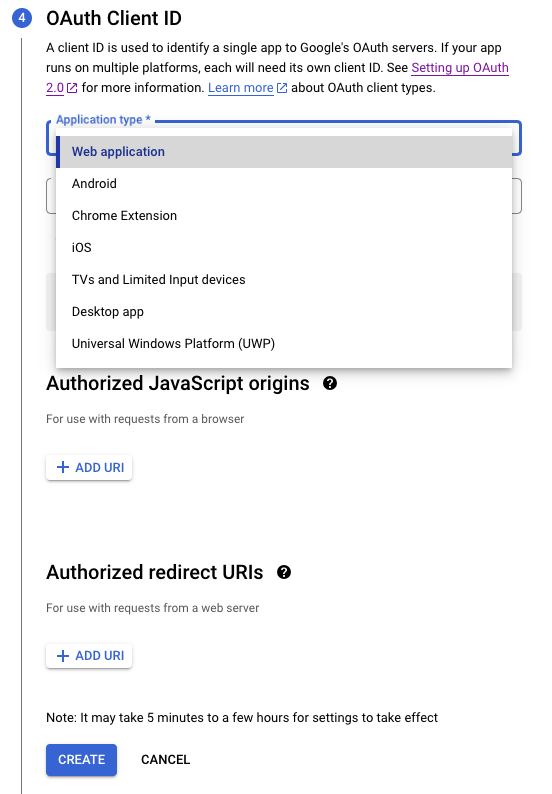
API Key와 마찬가지로 좌측 Credentials메뉴를 클릭하고 들어간 화면의 상단에 + CREATE CREDENTIALS을 클릭하면 아래와 같이 어떤 서비스에 OAuth를 사용할지를 물어봅니다. 필요에 따서 앱타입을 선택하시고요.
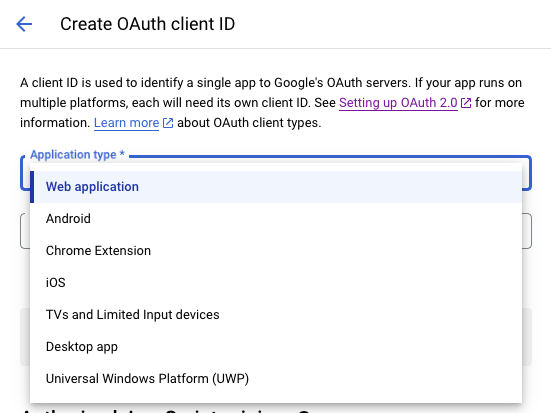
앱의 이름도 적어줍니다.
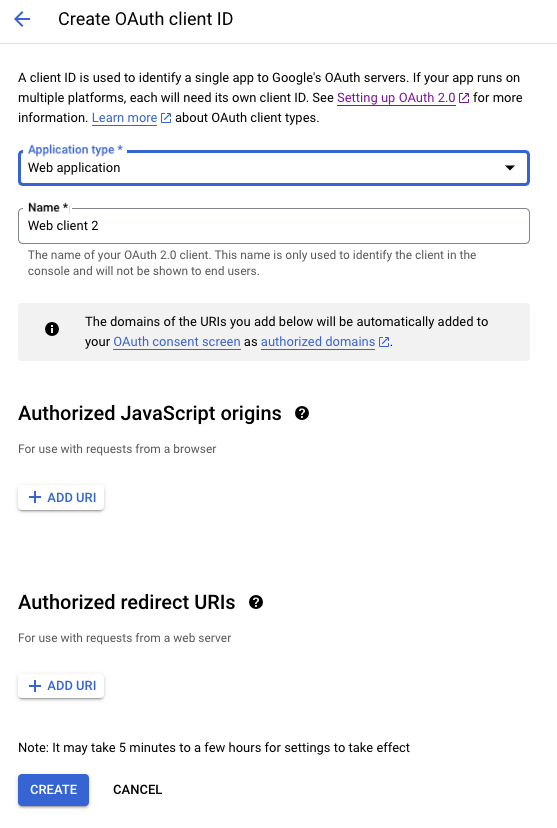
필요한 정보를 넣고 CREATE버튼을 클릭하면, 다음과 같이 Client ID와 Client Secret을 만들어 줍니다.

Scope정하기
OAuth를 사용하려면 접근가능한 범위를 지정해야합니다. Google Auth Platform > Data Access를 열어보시면 아래와 같은 화면이 뜹니다.
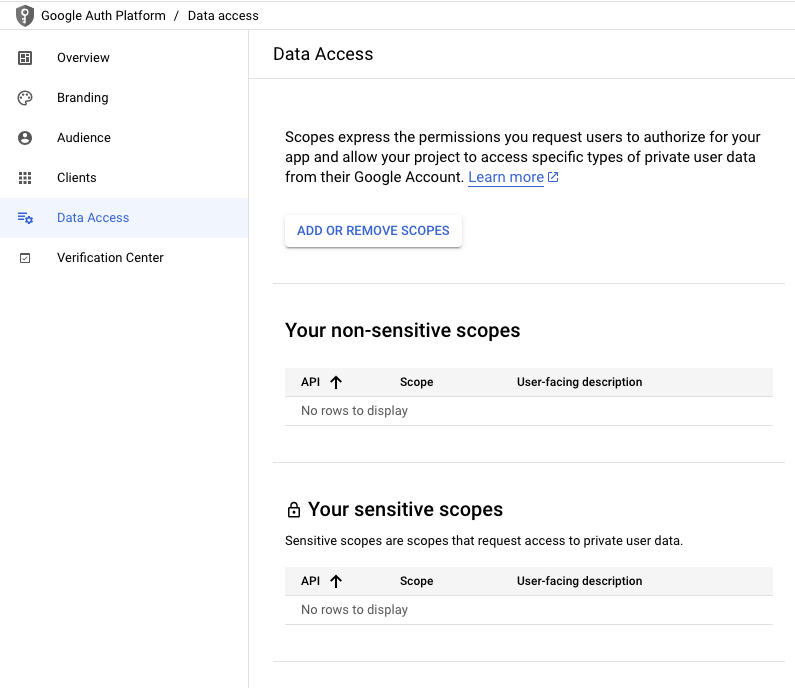
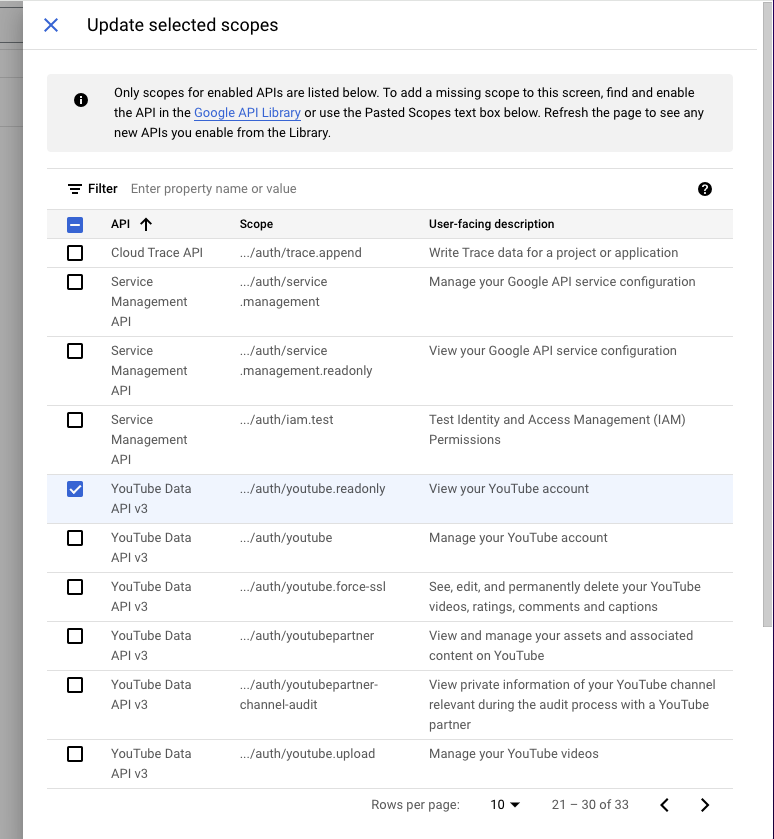
중간에 ADD OR REMOVE SCOPES를 클릭합니다. 그러면 어떤걸 접근을 풀어주고, 어떤걸 접근을 막을지 선택하는 곳입니다. 저는 YouTube Data API v3에서 읽는것만 일단 허용하도록 하겠습니다. 선택하고 나서 반드시 밑에 숨어있는 UPDATE버튼을 반드시 눌러주셔야합니다. 안그러면 저장이 되지 않습니다. 그리고 팝업을 닫고 Save버튼을 눌러서 변경된 Data Access내용들을 저장해주세요. Scope을 어떤걸 선택했는지는 따로 노트해두세요. 나중에 인증할때 필요합니다. 저는 테스트니까 안전하게 YouTube Data API v3의 .../auth/youtube.readonly만 선택하도록 할게요.
Redirect URI정하기
Google Auth Platform에서 좌측메뉴 Clients를 클릭하시면 현재 소유하고 있는 Client 들의 목록이 나오는데요
이중에 사용하고 싶은 클라이언트를 선택하세요. 그러면 아래와 같이 클라이언트에 대한 상세정보가 나타납니다.
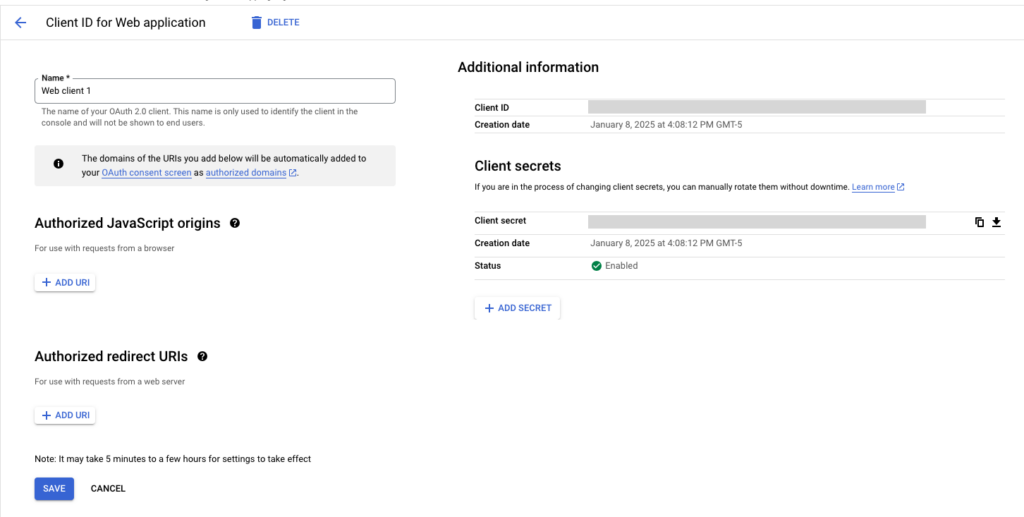
여기에서 + ADD URI버튼을 클릭해주세요. 그리고 나타난 텍스트상자에 인증코드를 받아서 돌아갈 주소를 넣어주세요. 그리고 SAVE버튼을 눌러서 저장합니다. 그리고 방금 저장한 Redirect URI는 인증코드를 받을 때 필요하니까 어딘가에 노트를 해두세요.

Test User추가하기
인증테스트를 하려면 앱을 출시하기 전에 접근을 할수 있는 사용자를 등록해야 테스트를 할수 있습니다. APIs & Services의 OAuth consent screen을 클릭하시면 테스트 사용자를 등록할 수 있습니다.
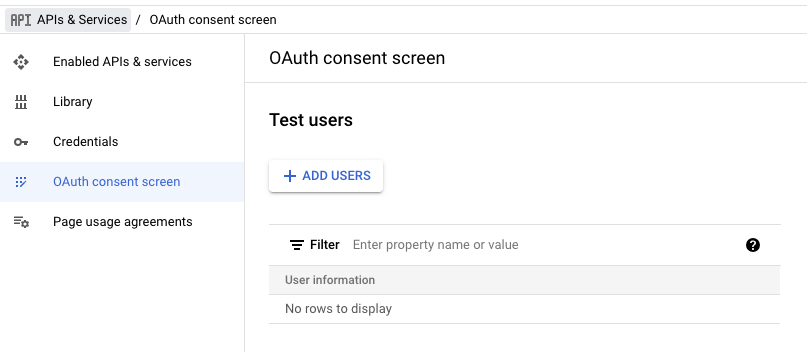
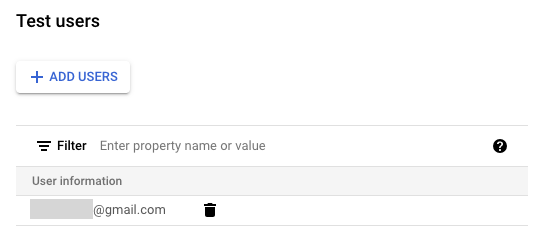
+ADD USERS버튼을 누르면 슬라이드팝업이 뜨는데 여기에 접근을 허용하고자 하는 이메일을 입력한 뒤 SAVE버튼을 클릭하세요. 그러면 아래와 같이 테스트사용자가 들어갑니다.
Access Token 받아오기
타 서비스의 OAuth인증과 마찬가지로 API토큰을 받아오기 위해서 일단 Code를 받아와야합니다. 여기에서 방금 선택한 Scope과 Redirect URL,그리고 Client ID를 다른 파라메터들과 함께 넘겨줍니다. 지금은 테스트하는거니까 코드로 안하고 그냥 브라우저 주소창에 호출할게요.
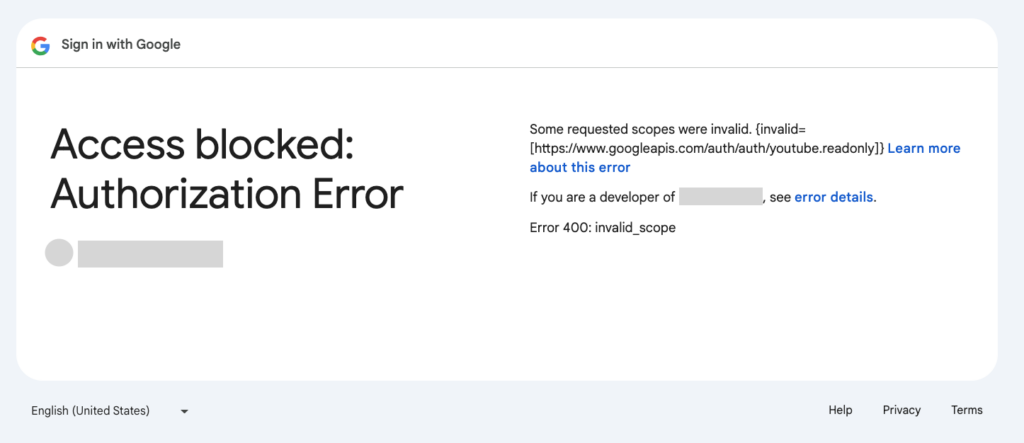
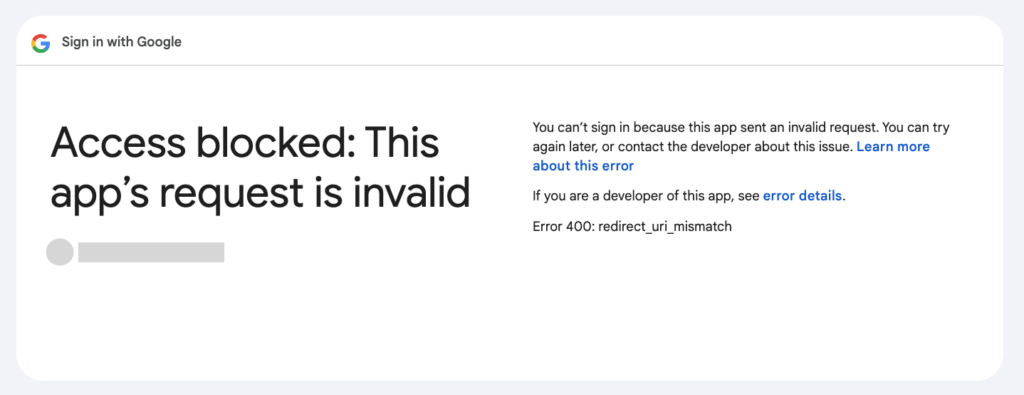
https://accounts.google.com/o/oauth2/v2/auth?scope=SCOPE&include_granted_scopes=true&response_type=token&state=state_parameter_passthrough_value&redirect_uri=REDIRECT_URI&client_id=CLIENT_ID문제가 생기면 에러를 보여줍니다. Error메세지를 읽어보면 Scope이 문제인지 Redirect URI가 문제인지 아니면 또 다른 문제인지 자세히 알려줍니다.
Scope, Redirect URI, Client ID모두 문제가 없으면 어떤 계정으로 인증을 진행할것인지를 물어봅니다. 해당 클라이언트 ID를 생성했던 계정을 선택하셔야해요.
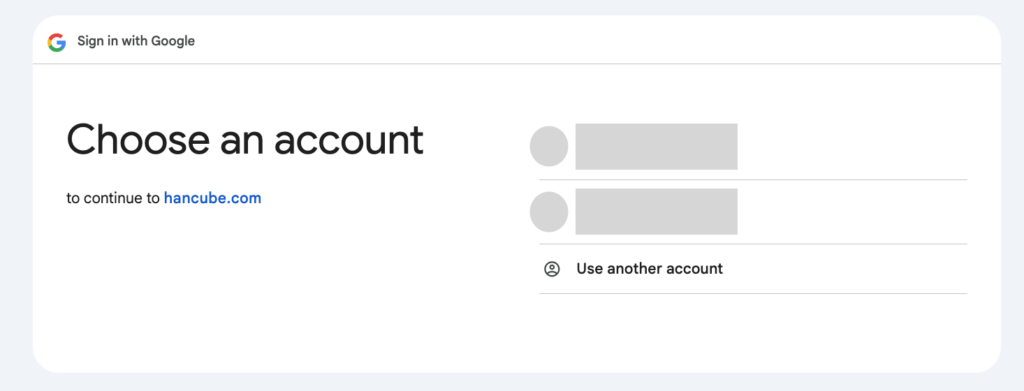
테스트사용자로 등록된 사람이 접근을 시도하면 아래와 같은 에러가 날거에요.
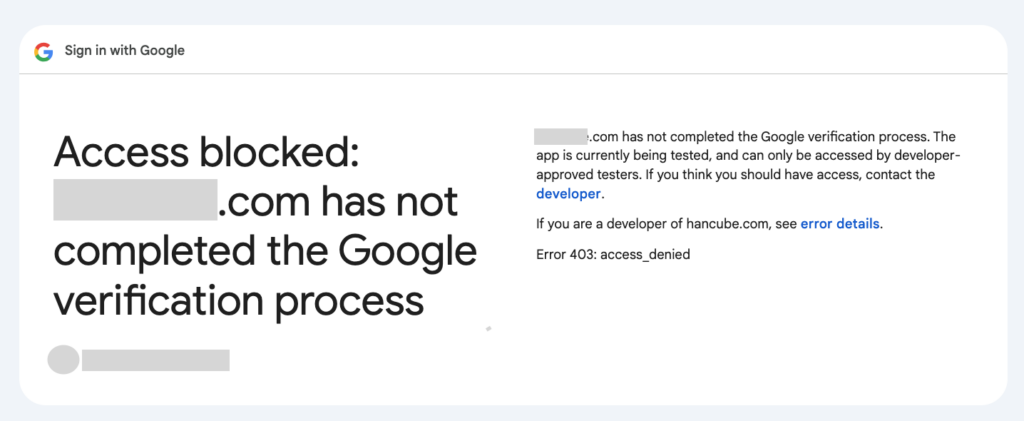
해당 계정이 테스트 사용자라면 다음과 같은 안내문이 뜨고 Continue를 누릅니다.
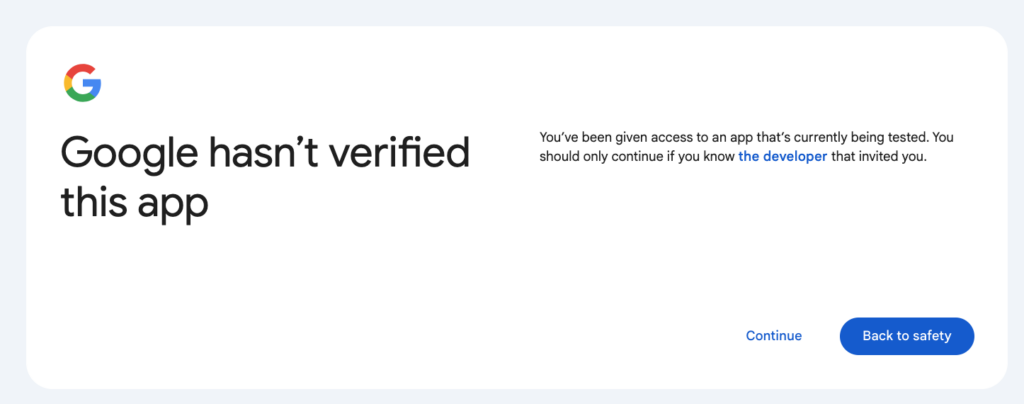
지정한 도메인이 클라이언트가 되고 이제 테스트사용자의 계정을 통해서 해당 클라이언트가 API에 접근을 하려고 한다고 경고문을 보여줍니다. Continue를 누릅니다.
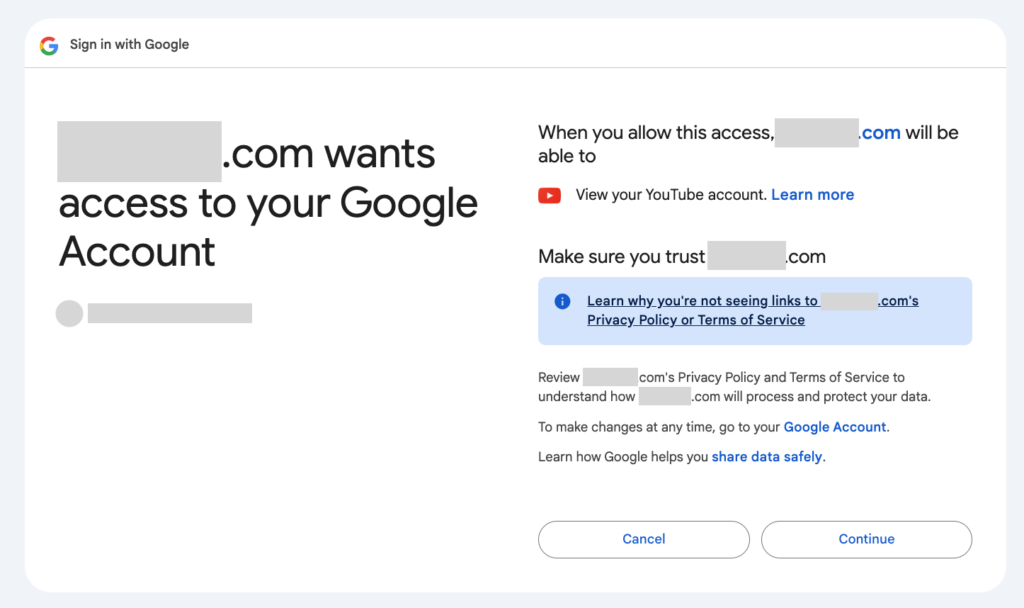
그러면 Redirect URI에 명시한 대로 해당 주소로 이동되며, 주소에 access_token을 함께 전달합니다.
https://REDIRECT_URI/#state=state_parameter_passthrough_value&access_token=ACCESS_TOKEN&token_type=Bearer&expires_in=3599&scope=https://www.googleapis.com/auth/youtube.readonlyAPI 호출 with API Explorer
이제 토큰을 가지고 API를 호출해볼까요? Google API Manual에 가면 Authorization하는 부분이 있는데 거기에서 API를 실행할 수 있는 양식이 준비되어 있습니다.
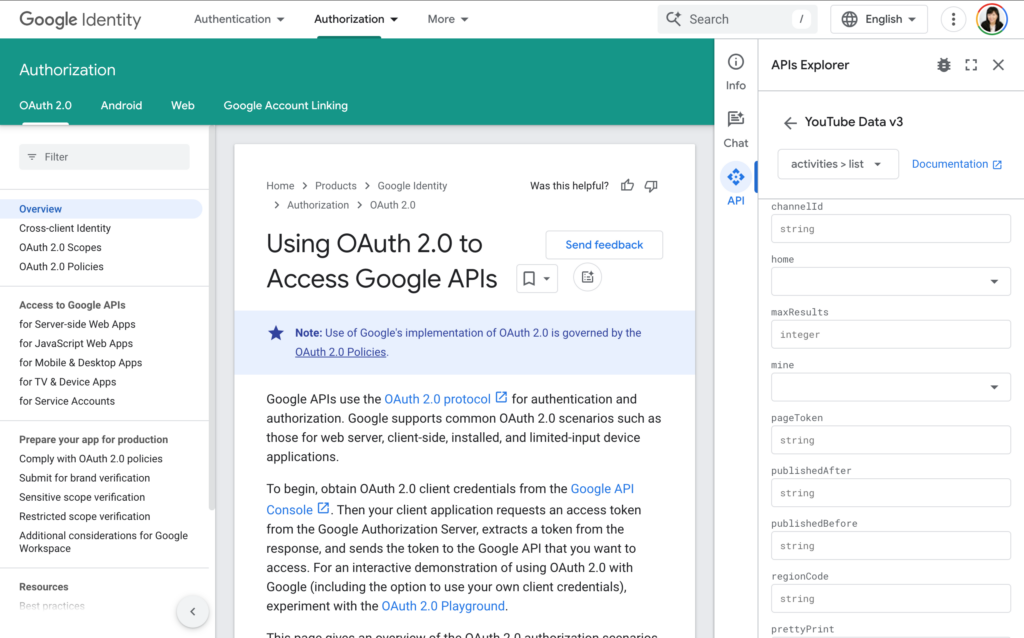
텍스트상자중에 access_token을 찾아서 방금 받아온 Access Token을 입력하신 뒤에 맨 밑에 Execute버튼을 누르세요. 이때 API Key체크상자는 체크를 해지한뒤에 눌러주세요.
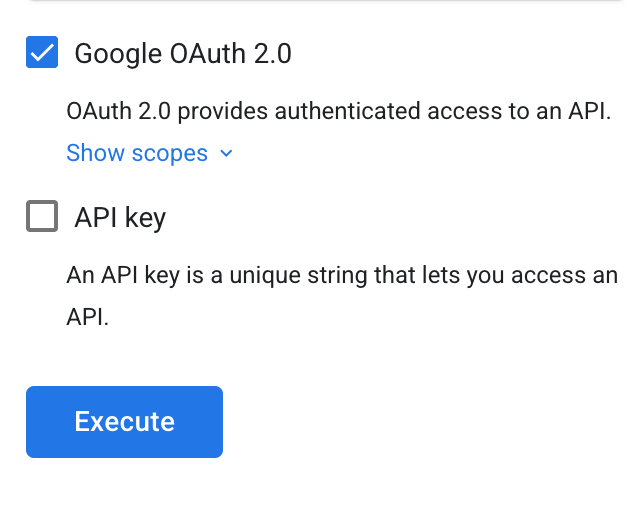
그러면 진행할 계정을 선택하라고 나옵니다. 사용하고자 했던 클라이언트를 만든 계정을 선택하세요.
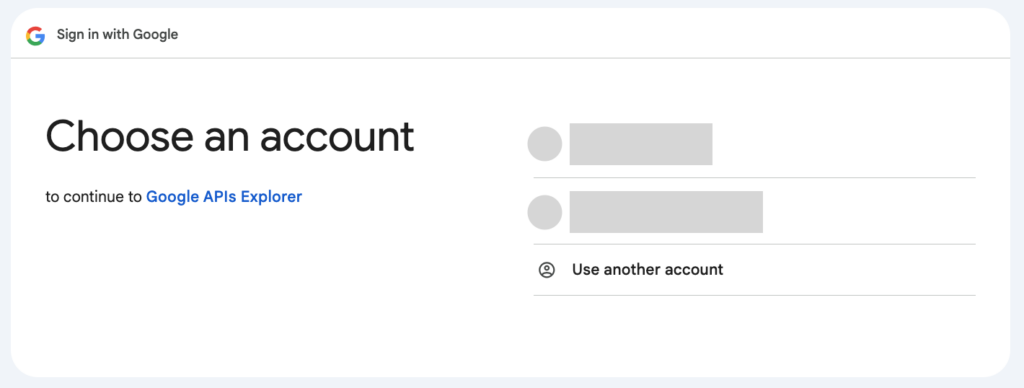
계속하면 개인정도등이 공유된다고 경고메세지를 보여줍니다. Continue를 눌러주세요.
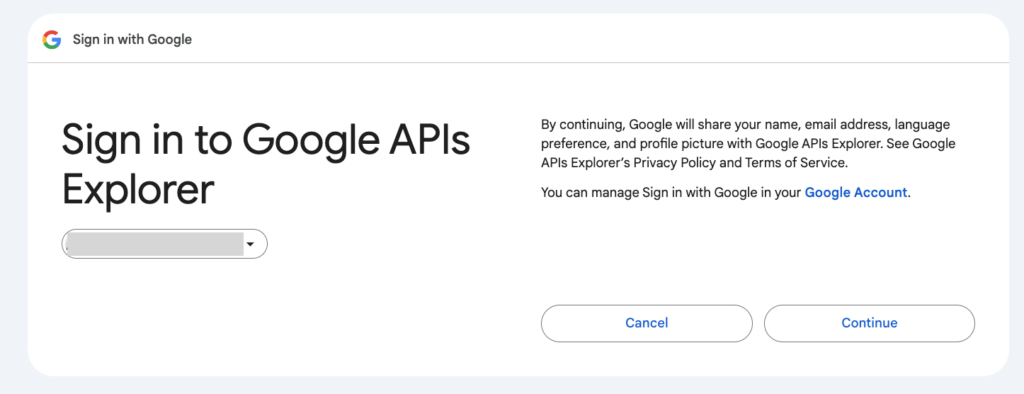
그러면 본인의 계정에 접속하여 갖가지 데이타를 추가, 수정, 삭제할 수 있는 권한을 이 클라이언트 앱에 할당 할지를 물어봅니다. Allow버튼을 눌러주세요.
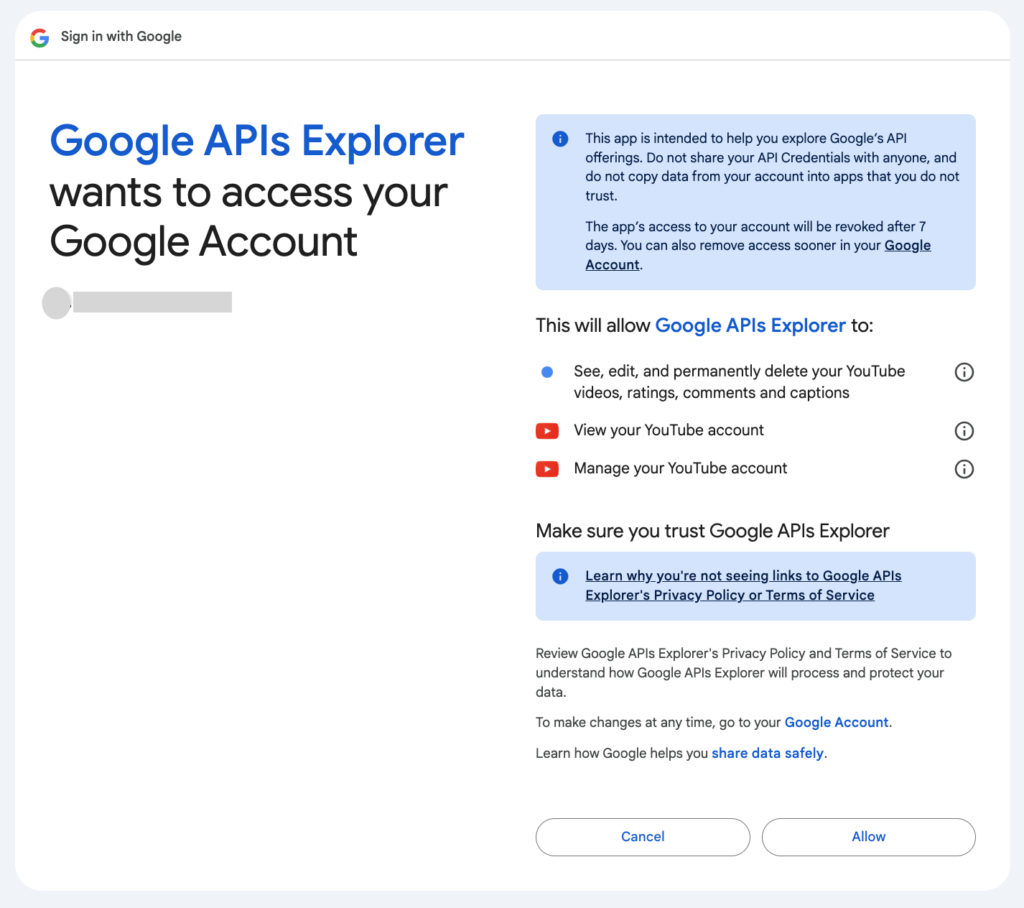
위에서 Allow버튼을 누르면 팝업이 닫히고 APIs Explorer의 Execute버튼 밑으로 API결과를 보여줍니다.
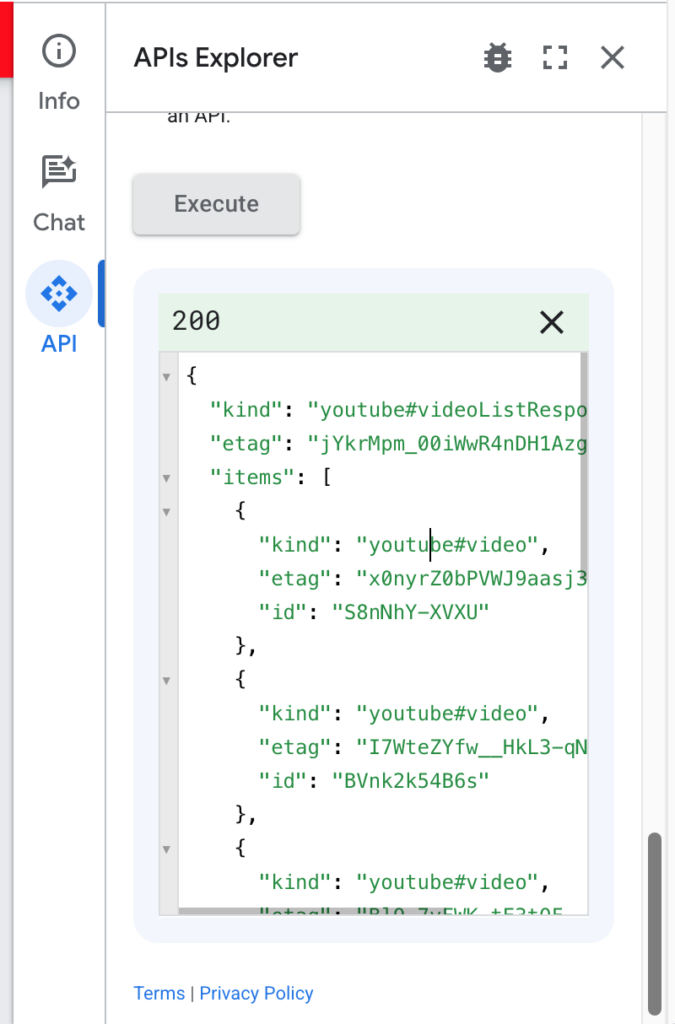
API Key를 없애려는 구글의 노력
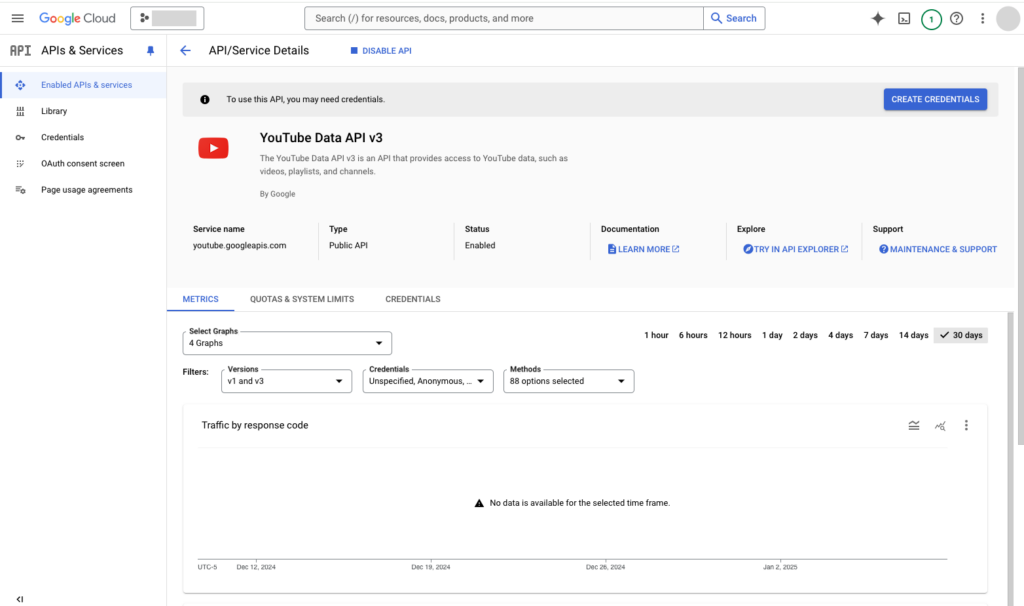
프로젝트를 생성하면 바로 APIs & Services 의 Enabled APIs & services로 트래픽현황을 볼수 있는데요. 상단에 CREATE CREDENTIALS이 큼지막하게 보입니다. 아마도 좌측메뉴를 눌러서 API Key를 생성하기 전에 OAuth로 인증을 받도록 유도하려는 의도인것 같습니다.
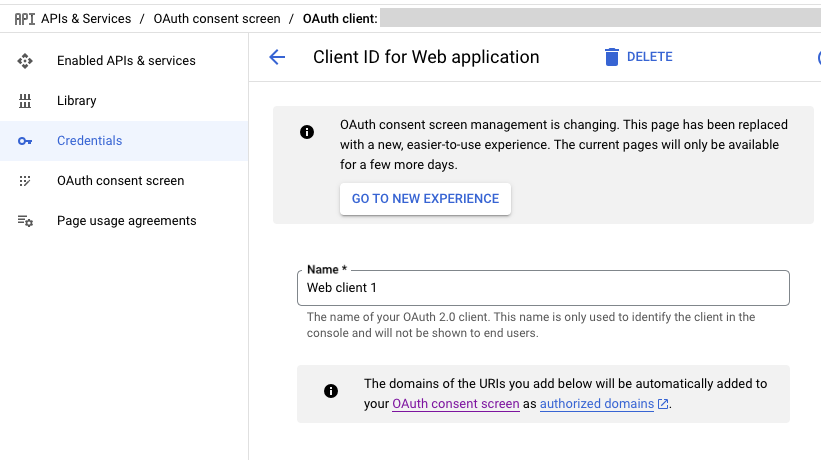
Credentials > Clients
APIs & Services > Credentials은 이제 사라지고 앞으로는 Google Auth Platform > Clients에서 관리가 될것이라고 공지가 뜨네요.
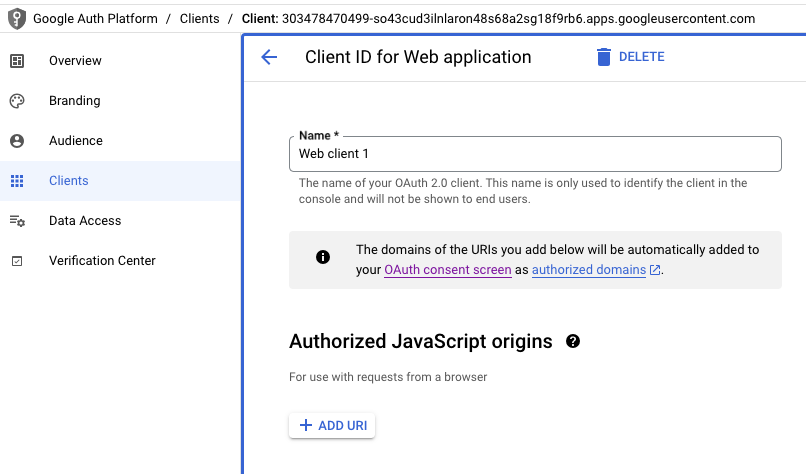
OAuth consent screen > Audience
APIs & Services > OAuth consent screen도 이제 Google Auth Platform > Audience로 옮겨간다고 합니다.
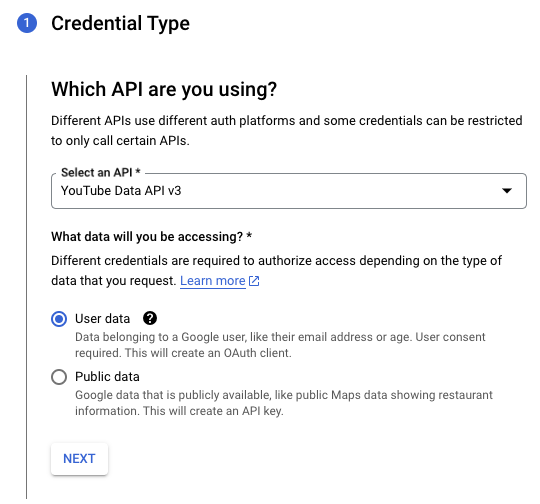
Create Credentials는 OAuth만 지원
위의 화면에서 CREATE CREDENTIALS버튼을 클릭해보면 아시겠지만 인증종류를 물어보지도 않고 그냥 OAuth로 정해서 생성하도록 구성되어있습니다.
Credential Type
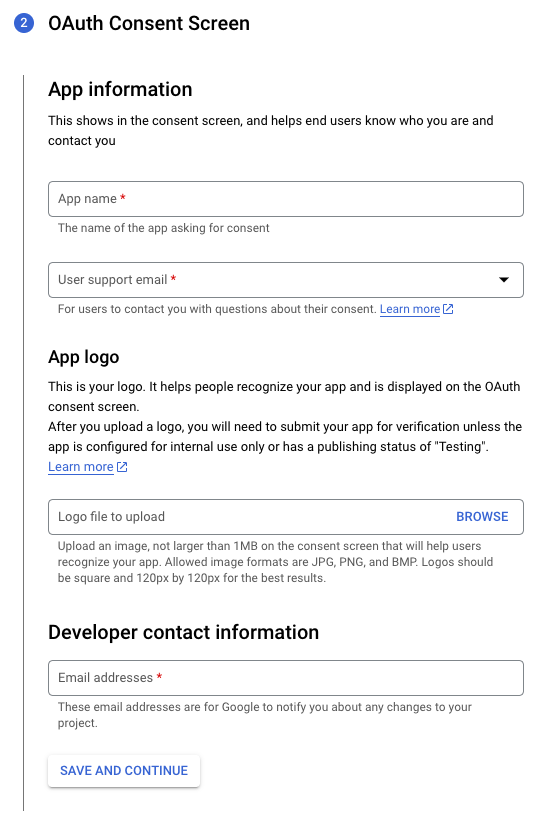
OAuth Consent Screen
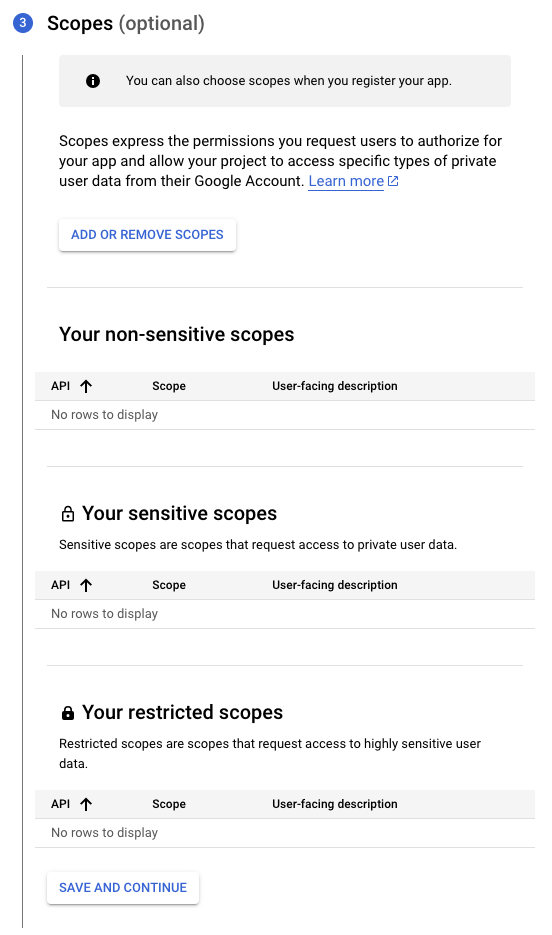
Scopes
OAuth Client ID
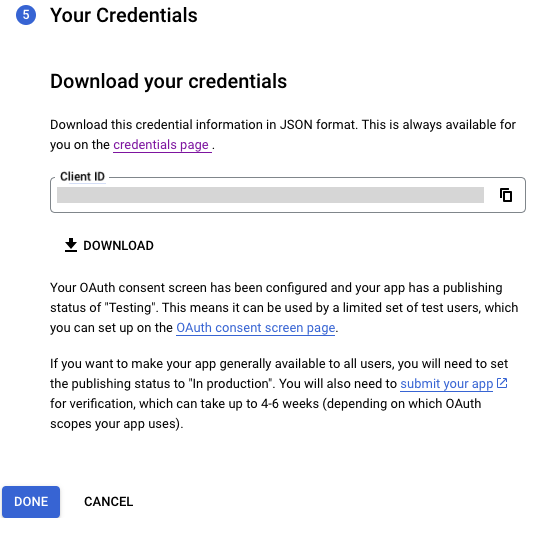
Your Credentials
몇가지 화면만 봐도 API Key는 앞으로 사라지게 될것 같네요.
마무리
여기까지 Google의 API에 접근해서 데이타를 가져오는 방법에 대해서 간략하게 설명드렸습니다. OAuth로 생성한 Client ID를 제대로 활용하려면 지정한 도메인에서 돌아가는 Web앱이나, iOS, 또는 안드로이드 앱이 있어야 합니다. 사용하려는 곳의 출처를 웹앱이라면 도메인으로 소유권을 증명하고, 모바일 앱은 앱스토어 아이디등으로 누가 어디서 사용하는지를 명확히 명시해야합니다. 아마도 API를 악용하는 경우를 방지하기 위해서 2차 3차 검증을 하는 것으로 사료됩니다. API를 이용할 수 있는 웹앱이 만들어지면 그때 코드로 호출하는 방법에 대해서 알아보는 시간을 갖도록하겠습니다. 수고하셨습니다. 좋은 밤되세요!
References
- YouTube Data API Reference
- Using OAuth 2.0 to Access Google APIs
- Use API keys to access APIs
- Manage API keys
- Javascript 웹앱용 OAuth Client
- Quick Start Sample with Python
- Access blocked: App not completed the Google verification process error in oauth2